Every major open-weights frontier model - GLM 5, Ring 1T, DeepSeek V3.2, Minimax M2.5, Qwen 3.6 - uses async RL. It's up to 2-3x faster than the alternative but it can easily collapse mid-training. Each lab quietly built their own workaround but none of them fully work. This is the story of why.
What Is Async RL and Why Does Everyone Want It
A big systems problem in RL is that sampling is expensive. In standard on-policy RL, you first sample prompts, generate responses with the current model, and only then train on those responses. This makes the loop conceptually simple, but even one trajectory that takes much longer than the others can hold up the next update and leave some compute underused.
Asynchronous RL removes this bottleneck by separating generation and training into two independent loops. As the diagram below shows, rollout workers keep producing trajectories while the trainer keeps updating the policy, no waiting required.
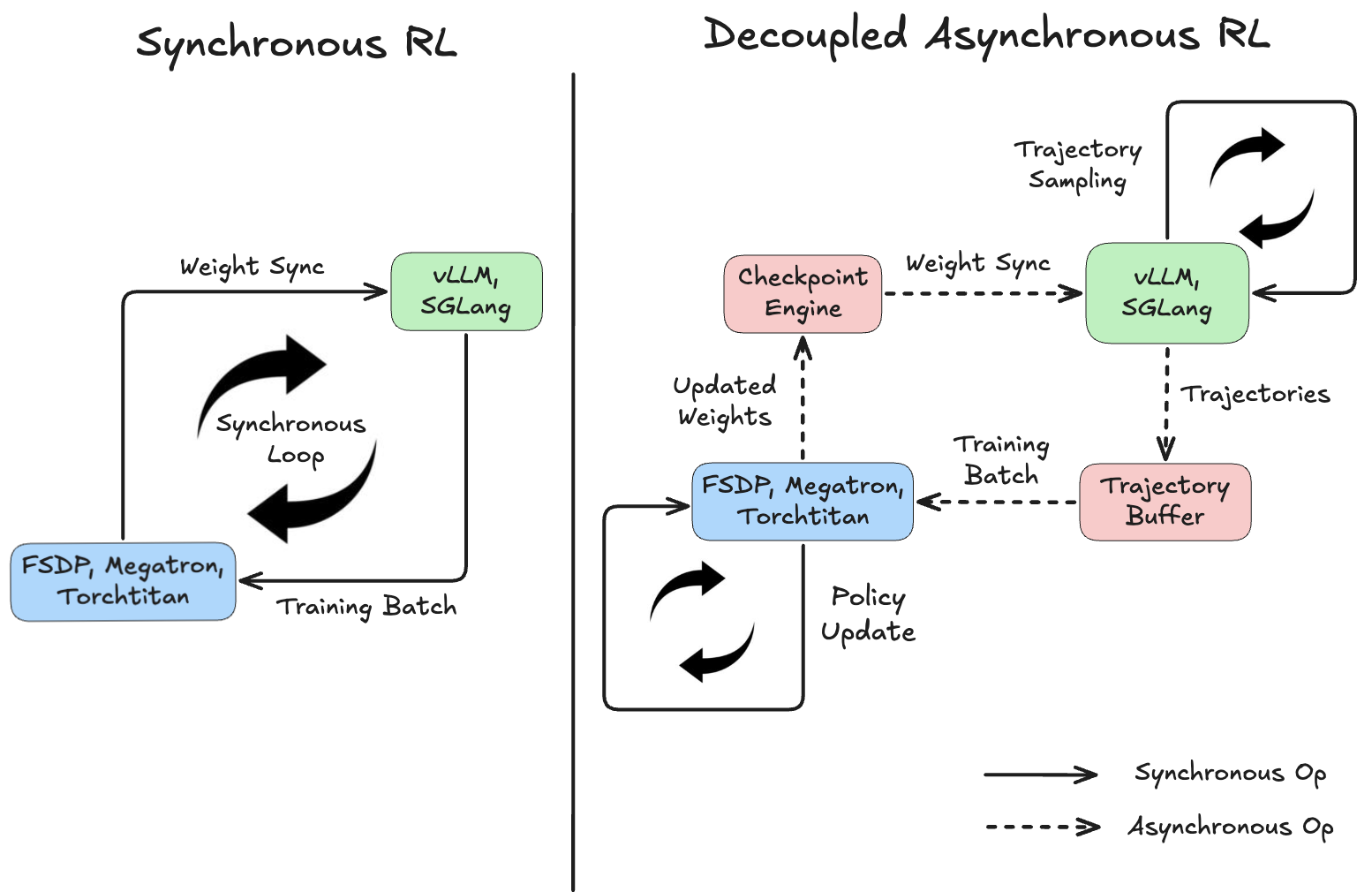
This decoupling is why many practical RL systems have moved to async pipelines, and why recent open model releases including GLM-5, Ring-1T, Qwen3.5, and Kimi K2.5 already adopt asynchronous RL at scale. The same trend is reflected in open-source infrastructure such as AReaL, LlamaRL, PipelineRL, and Slime.
The catch is that the generated data is now stale. The policy used to produce those trajectories is no longer exactly the same as the policy being trained. This means async RL is off-policy.
In principle, we can use importance sampling to correct this mismatch. Formally, the off-policy objective uses importance sampling to reweight each trajectory by how much more (or less) likely the current policy thinks it is compared to when it was generated by the inference policy:
The importance-sampling (IS) ratio is doing the corrective work. But as the policy drifts further from the behavior policy, those ratios can become extreme, and that's where the instability starts to appear.
The Staleness Problem
A useful way to describe this mismatch is by the policy lag K: the number of optimization steps by which the training policy is ahead of the inference policy. When K = 0, training is fully on-policy. As K grows, the data becomes more stale. Many frameworks constrain this staleness by only allowing the trajectory buffer to contain samples within K steps of the current policy.
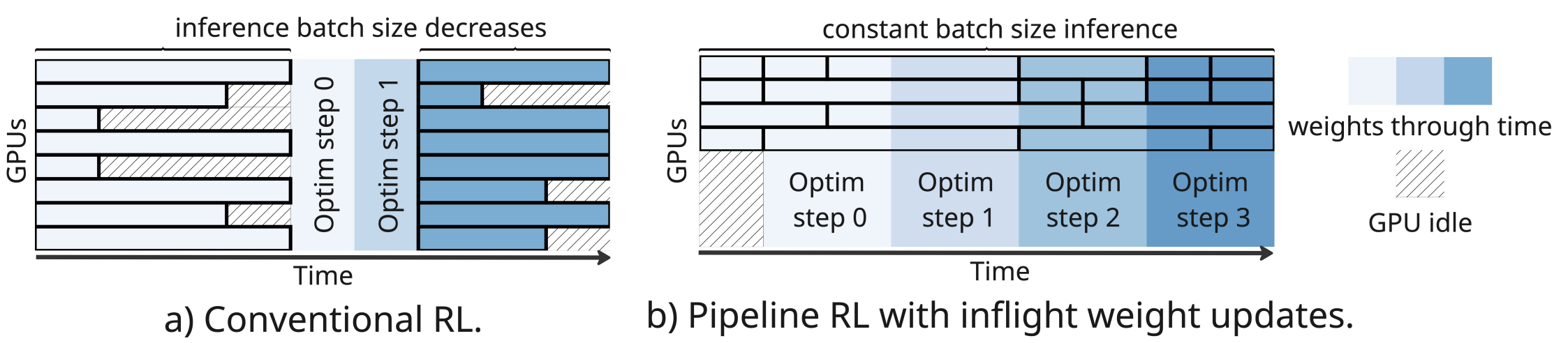
In this setting, \(K=\infty\) represents the theoretical ceiling of async RL, the speed you'd get if you didn't constrain staleness at all, training continuously on whatever trajectories are in the buffer. Although in practice, the steady-state policy lag converges to the ratio of inference throughput to training throughput. The problem is that long-horizon tasks - exactly where you most want async RL - are also the ones that demand the highest K to approach that ceiling. Look at what happens as sequence length grows:

At short sequences, \(K=4\) gets close to the update-only async ceiling in time per step. But as sequences get longer - which is exactly the regime of hard reasoning tasks, tool-use, and long-context problems - \(K=4\) remains above the \(K=\infty\) time-per-step ceiling. This means longer-horizon tasks create more pressure to push policy lag K up.
There are many ways to control staleness in a async RL setting. We can control the max staleness inside the replay buffer via either a FIFO queue, e.g. MiniMax, or sampling that throws away samples past a certain staleness level, e.g. like GLM-5.
2. Current State of Async RL Stability
GLM 5, Ring 1T, DeepSeek V3.2, Minimax M2.5 have all needed their own version of off-policy controls for stabilizing asynchronous RL at scale. Largely, most current methods are some form of reshaping the IS weights. There are some other methods with a few changes the estimator or changes to the infra to reduce training-inference mismatch that is additional to the fundamental off-policy from policy lag.
| Method | Description | Used In | Biased? |
|---|---|---|---|
| Truncated Importance Sampling (TIS) | Clip token or sequence ratios to a fixed range. | AReaL, LlamaRL | Yes |
| CISPO | Same as TIS. | Minimax-M2.5 | Yes |
| IcePop / Masked Importance Sampling (MIS) | Drop token, sequence, or geometric ratios outside a window. | Ring-1T, GLM-5 | Yes |
| DeepSeek Masking | Mask negative trajectories when average log-ratio is large. | DeepSeek-V3.2 | Yes |
| M2PO | Mask tokens until a second-order KL proxy is below threshold. | Yes |
2.1 Reshaping IS Weight: Masking and Clipping
Methods that reshape the importance weights try to reduce policy-gradient variance, at the cost of introducing some bias. The basic issue is already visible from the structure of the off-policy correction itself. Our off-policy objective in Eq. (1) uses the sequence-level importance ratio, which can be written as the product of token-level ratios:
The sequence-level weights \(w(\tau)\) is unbiased but it can be extremely high variance. Even if token-level ratios are moderately misaligned, multiplying them across a long trajectory can produce very large or very small sequence weights. At this point, there is a natural choice to make: should we work with token-level or sequence-level importance weights?
In the original PPO and GRPO formulation, token-level ratios are often good enough because consecutive policies are kept close. But async RL is different: the rollout policy can be many updates stale, so the real mismatch accumulates over the entire sequence. That makes sequence-level importance weights the more faithful description of the problem - but also the reason instability becomes so severe.
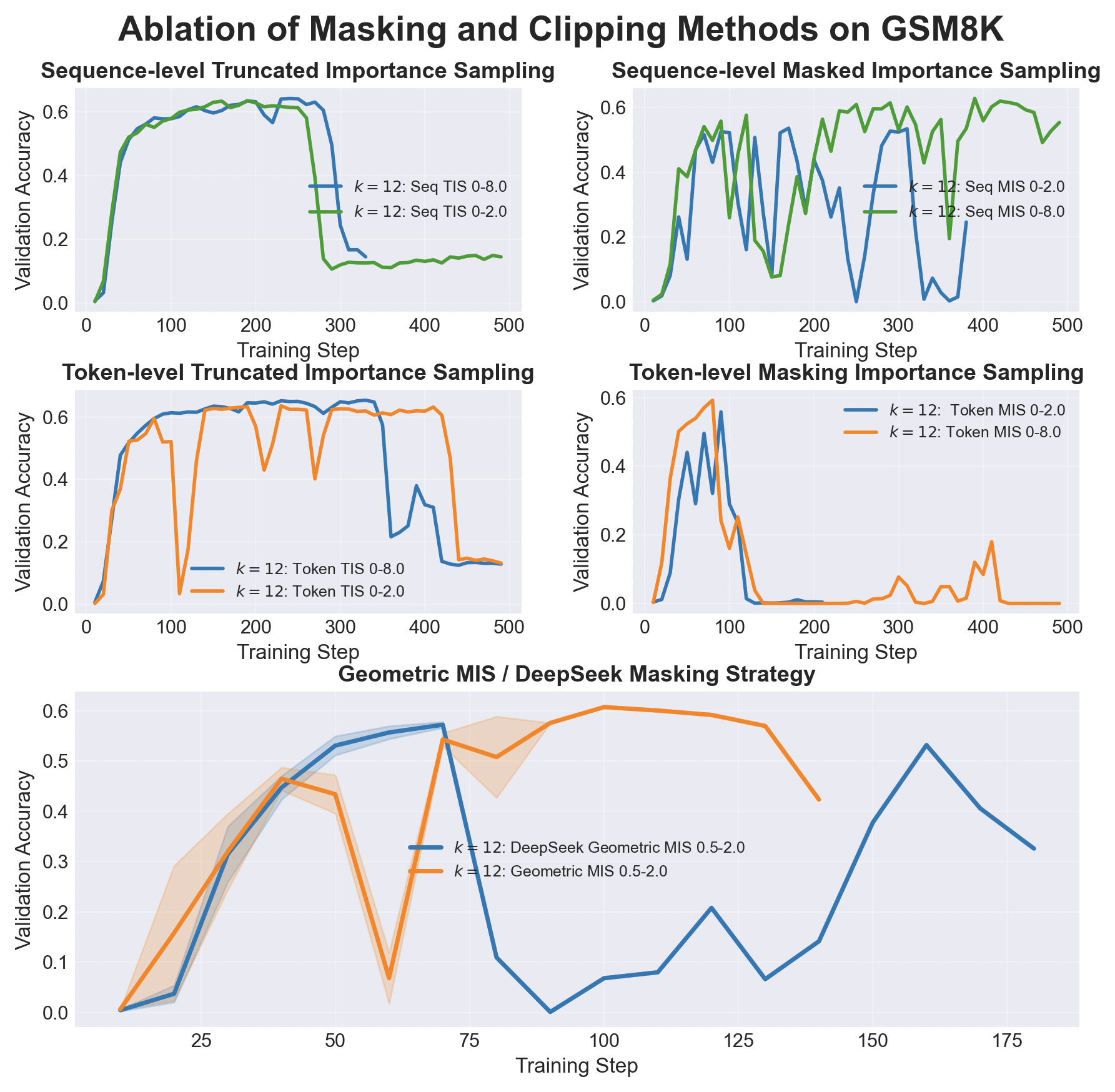
This is exactly why clipping and masking become so common in Async RL. Both try to prevent a small number of outlier ratios from dominating the gradient. Notably, GLM 5, Ring 1T, DeepSeek V3.2, Minimax M2.5 all use Clipping or Masking.
Clipping caps how extreme the token or sequence ratio is allowed to become. Masking is more aggressive. Instead, it drops sample entirely based on the token, sequence, or geometric-mean of the ratios. There are some alternative methods as well. M2PO proposes to drop tokens until the average squared log-ratio is less than some threshold. DeepSeek V3.2 uses a related idea at the sequence level: it keeps all non-negative samples, but masks negative trajectories once their average log-ratio becomes too large. MiniMax's CISPO uses clipping while allowing for gradient flow.
2.2 Instability at High-Policy Lag
So far, these defenses work reasonably well at low policy lag. At small K, async RL can be both fast and stable. At larger K, however, training can suddenly become fragile and even collapse.
We tested high policy-lag \(K=12\) training on GSM8k with Qwen2-1.5B, sweeping across the various clipping and masking strategies that have been proposed.
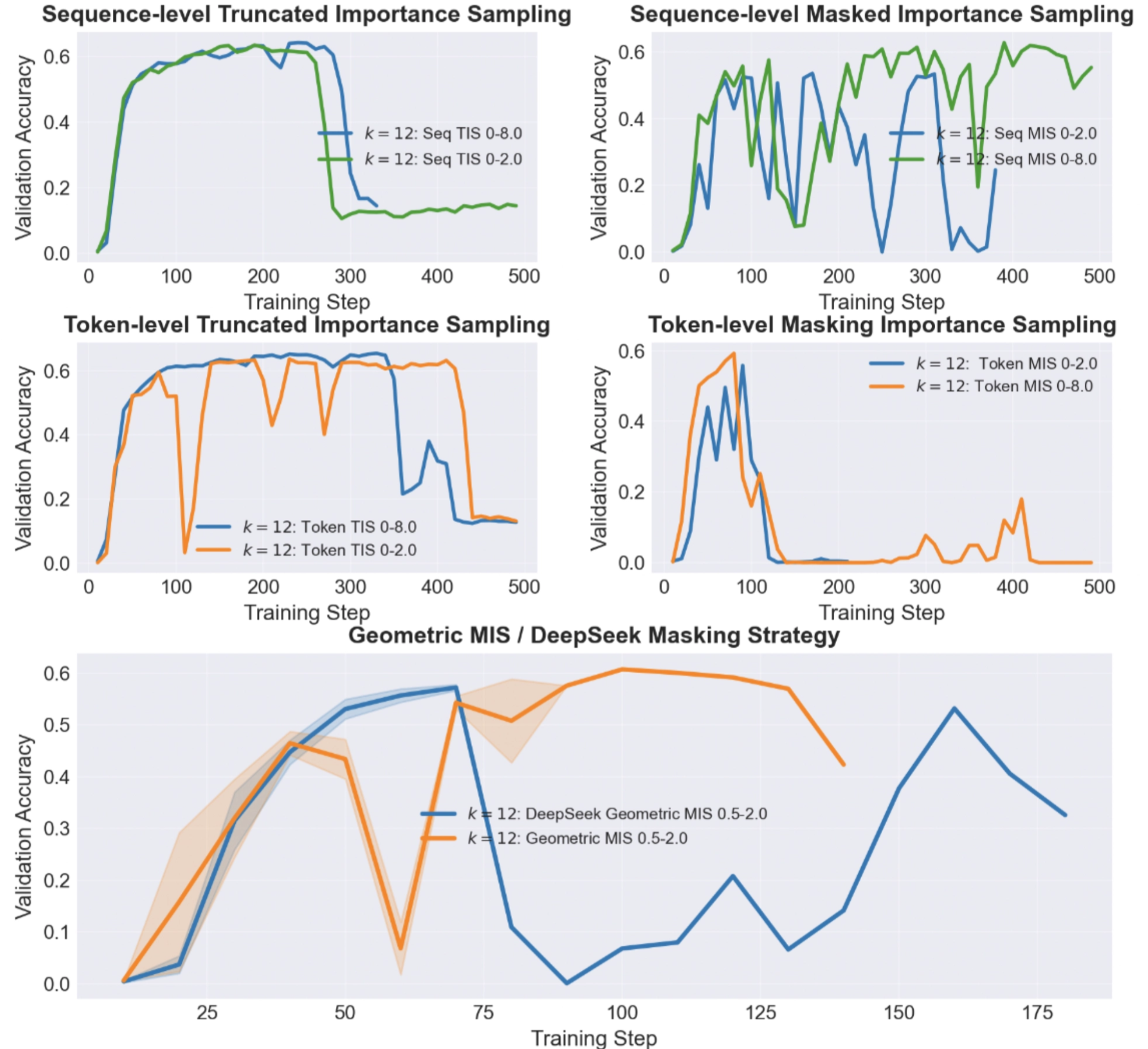
3. The First Warning Sign: Effective Sample Size
Once training becomes off-policy, not all trajectories contribute equally anymore. Some are still unrepresentative of the current policy, while others are very representative and need very large importance weights to increase their leverage. When that happens, the batch stops behaving like a batch of B independent samples and starts behaving like a much smaller one dominated by the higher importance weights.
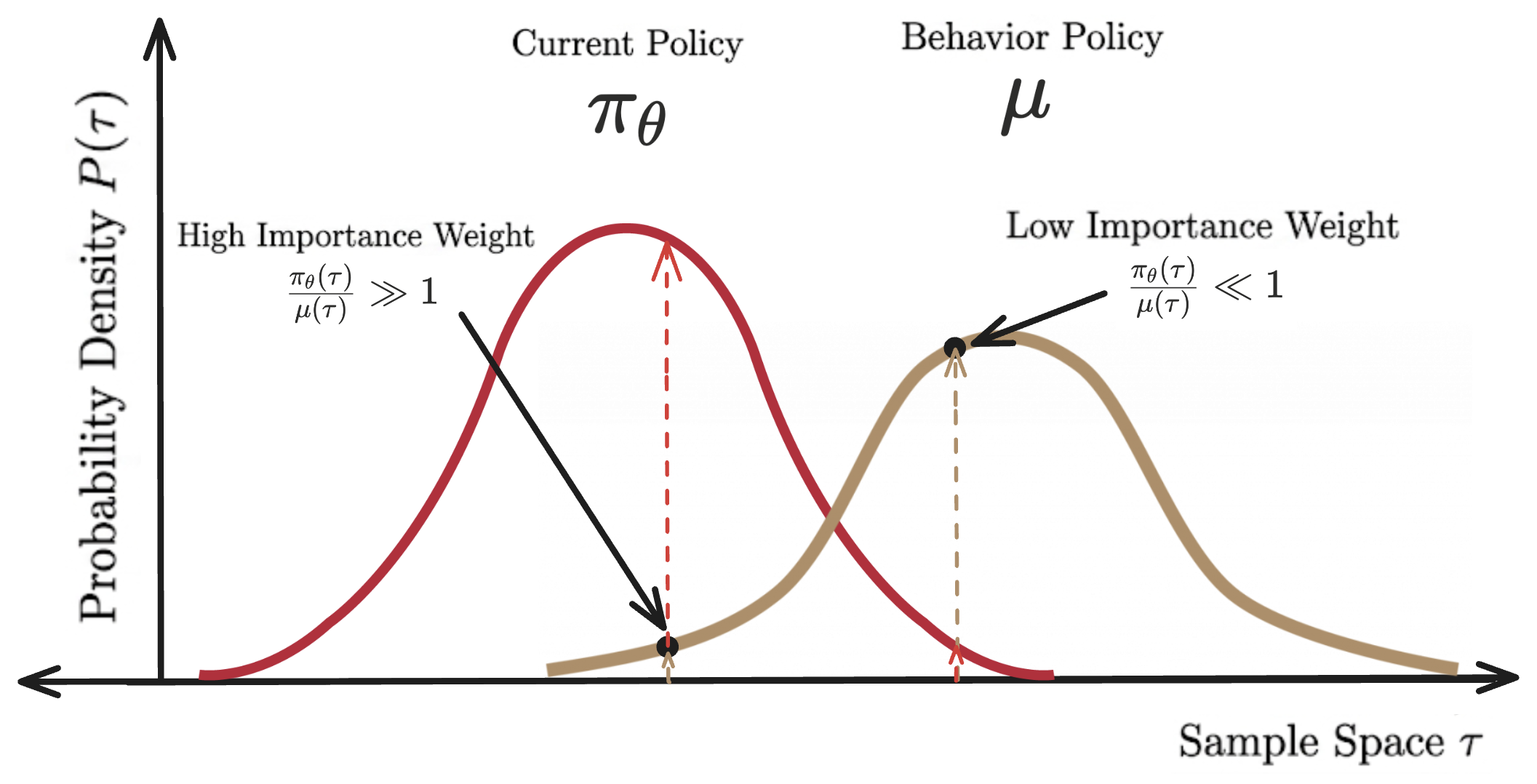
There is a statistics idea that measures this notion called the effective sample size, essentially measuring how many effective data points you have after accounting for the high importance weights dominating. A common diagnostic is the effective sample size (ESS):
The intuition is straightforward. When training is fully on-policy, all importance weights equal 1 and \(\mathrm{ESS}=B\) since you're getting full value from every sample. But when one trajectory dominates with a huge importance weight, ESS collapses toward 1 since you've effectively thrown away the rest of your batch. The variance of your gradient estimate scales as \(1/\mathrm{ESS}\), so a collapsing ESS means your updates are getting noisier and noisier.
The Effective Sample Size Collapse
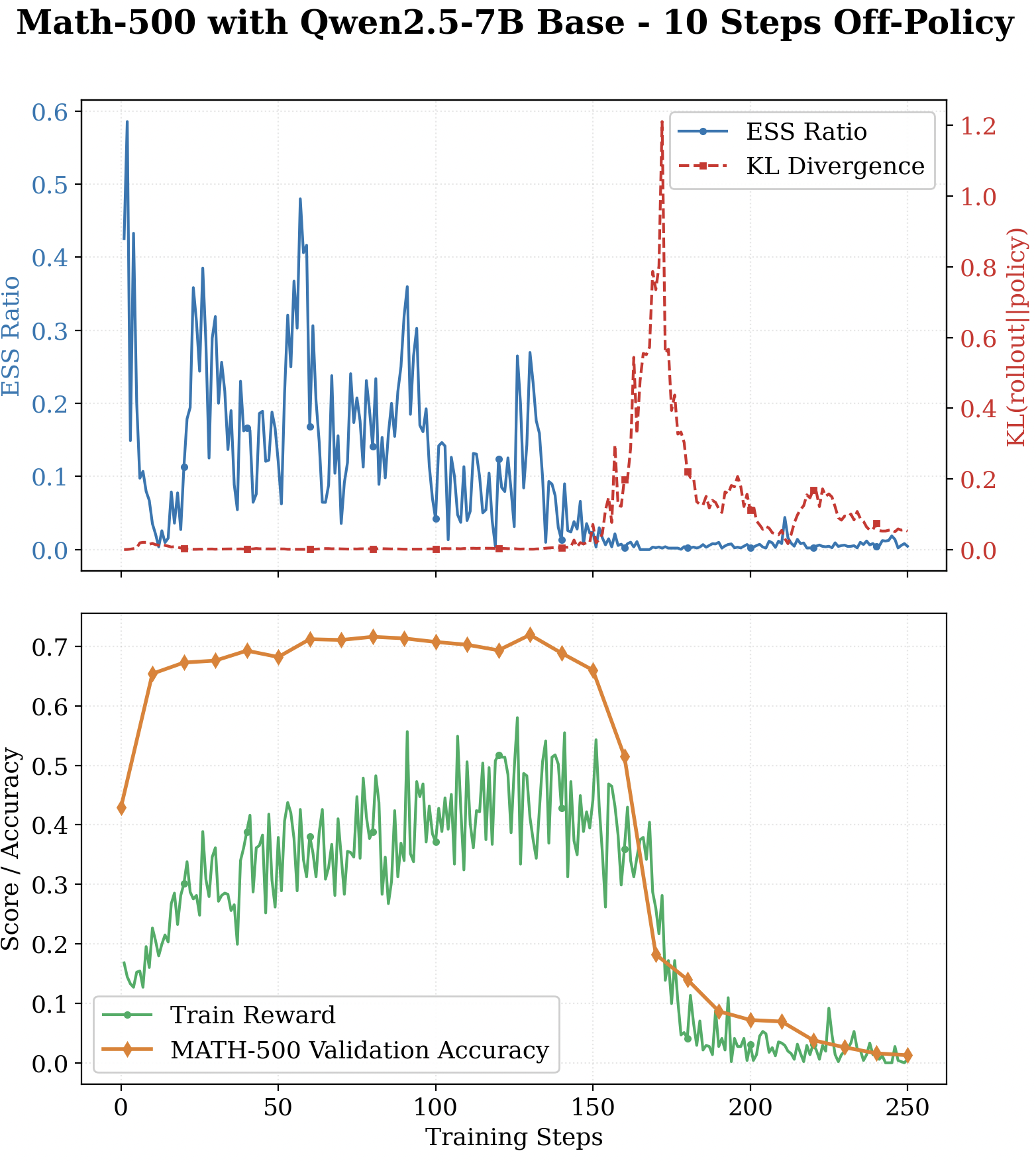
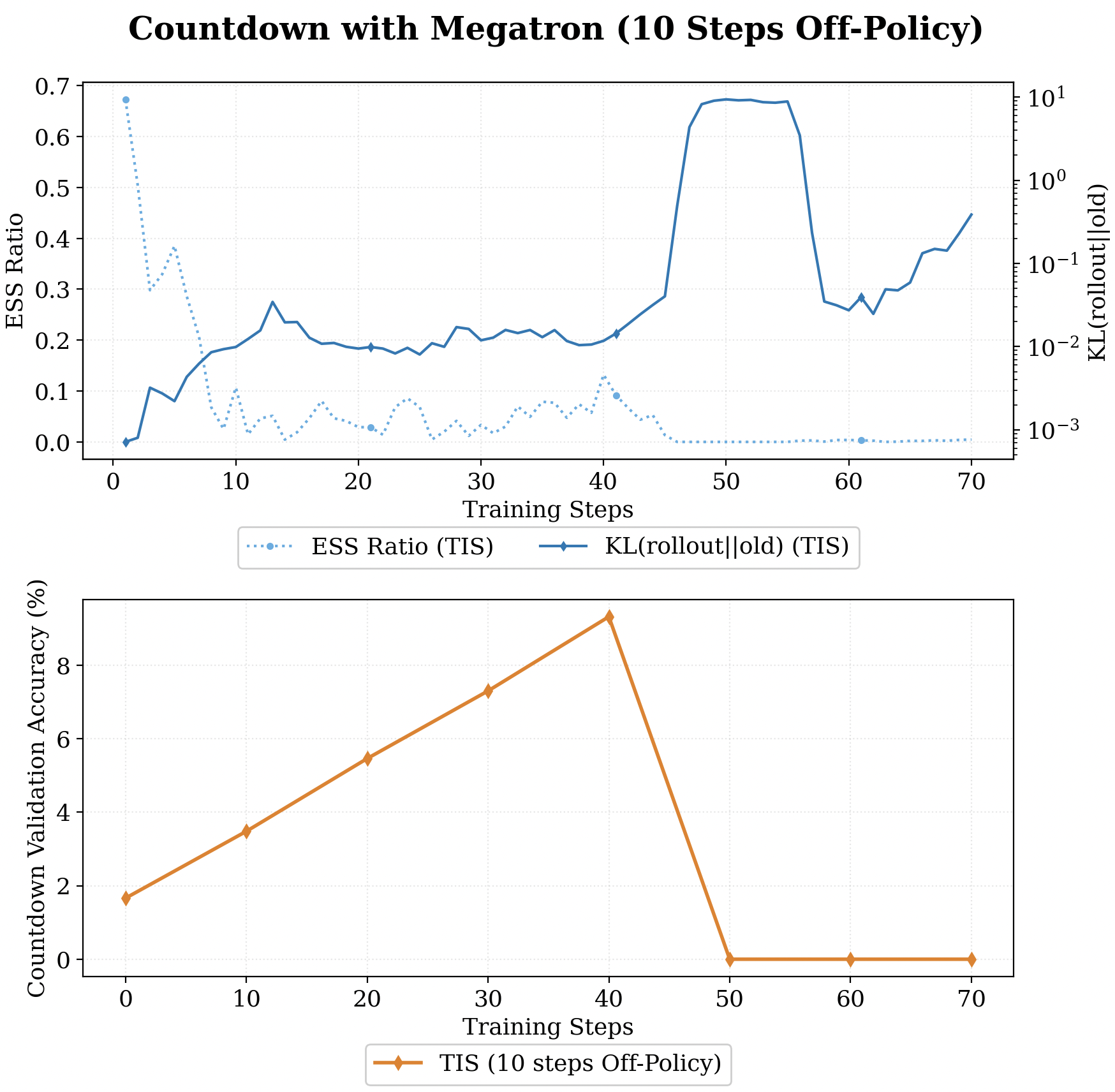
We tracked ESS across two async RL runs that were heading toward collapse - Qwen2.5-7B at \(K=10\) on MATH, and Qwen2-1.5B at \(K=12\) on GSM8k. The pattern was the same in both cases: ESS quietly declines long before the crash happens.
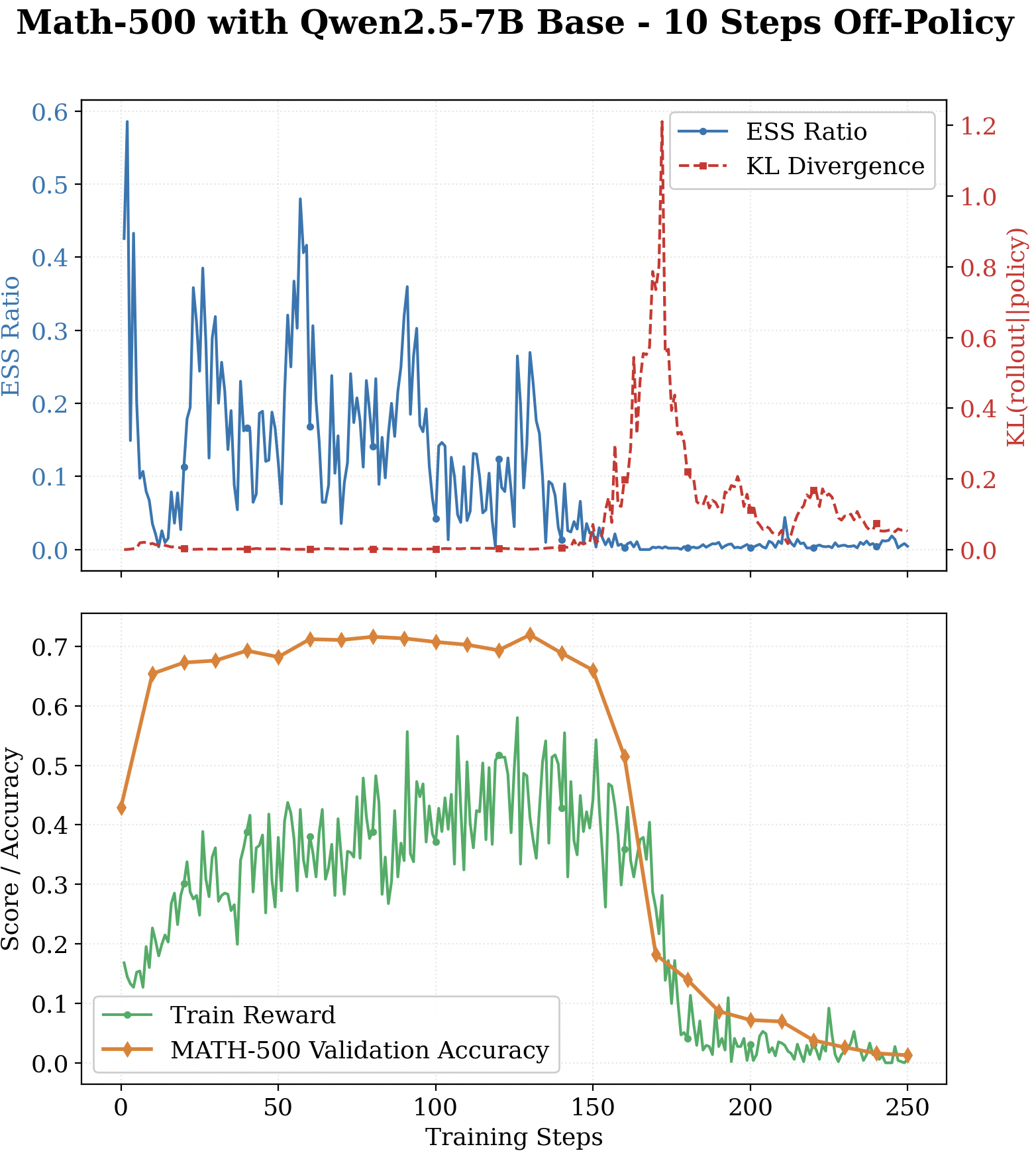
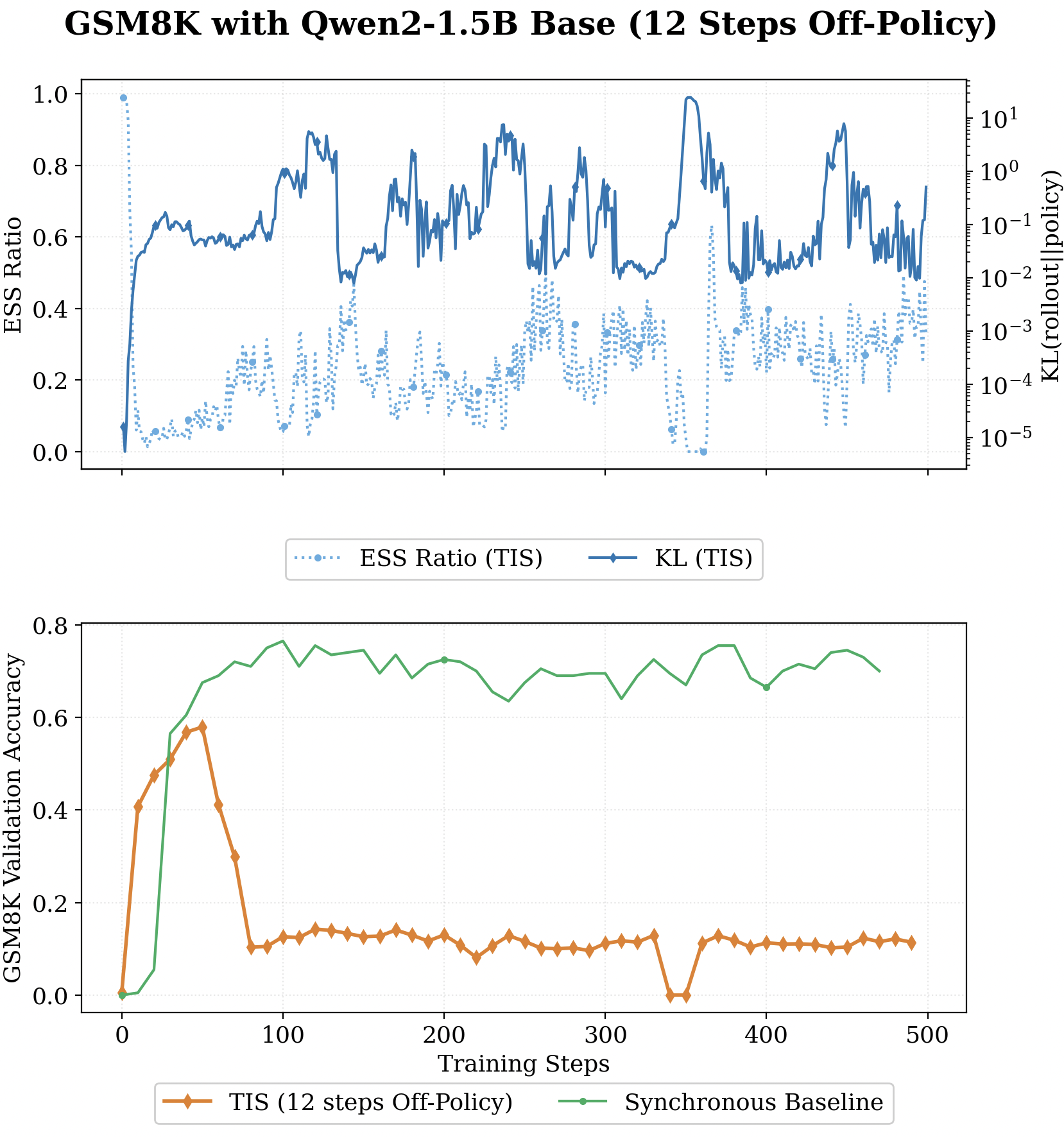
What This Means (and What Comes Next)
4. Fix #1: Take Smaller Steps on Noisy Batches
Similar to pretraining ideas of using gradient signal, we use ESS to find optimal learning rates for each batch. Motivated by the square-root scaling law \(\eta\propto\sqrt{B}\), we propose learning-rate scaling via an effective batch-size rule:
Show good results.
5. Another Problem: A Few Trajectories Can Dominate the Update
Unfortunately, there are some trajectories that have much larger gradient norms than other ones. This means some trajectories tend to dominate the update. Fortunately, there is a way to reduce the noise introduced these huge gradients, without adding bias to the gradient.
Baselining is a fundamental technique for reducing the variance of policy gradient without bias. In highly asynchronous training, however, importance weighting changes the variance structure. We thus derive the variance-minimizing baseline for an off-policy, importance-weighted policy-gradient estimator.
6. Fix #2: An Optimal Baseline for Off-Policy RL
Consider the off-policy gradient estimator with a scalar baseline b:
Optimal Off-policy Baseline. Minimizing \(\mathrm{Var}(\widehat{G}(b))\) over scalar \(b\) yields a closed-form solution for the off-policy optimal baseline (OPOB):
Compared to common group baselines, variance-optimal baselining in the off-policy regime depends on both the importance weights and the gradient magnitudes. Intuitively, samples that are both highly upweighted off-policy and induce large parameter changes dominate update variance and should therefore dominate the baseline.
6.1 Efficient Single Backward Pass Implementation
But how do we do a backward pass that requires the gradient information from the backward pass itself? Turns out we can exploit the linearity of our objective for a one backward pass implementation.
Thus, for any chosen b, the final gradient can be formed by combining two aggregated quantities G_R and G_S. We compute per-sample score gradients once and accumulate them into two gradient buffers:
- G_R: a buffer that accumulates the reward-weighted gradients.
- G_S: a buffer that accumulates the gradients.
Afterwards, we form the final update by a simple linear combination of these buffers. This avoids any additional backward pass to incorporate the baseline term.

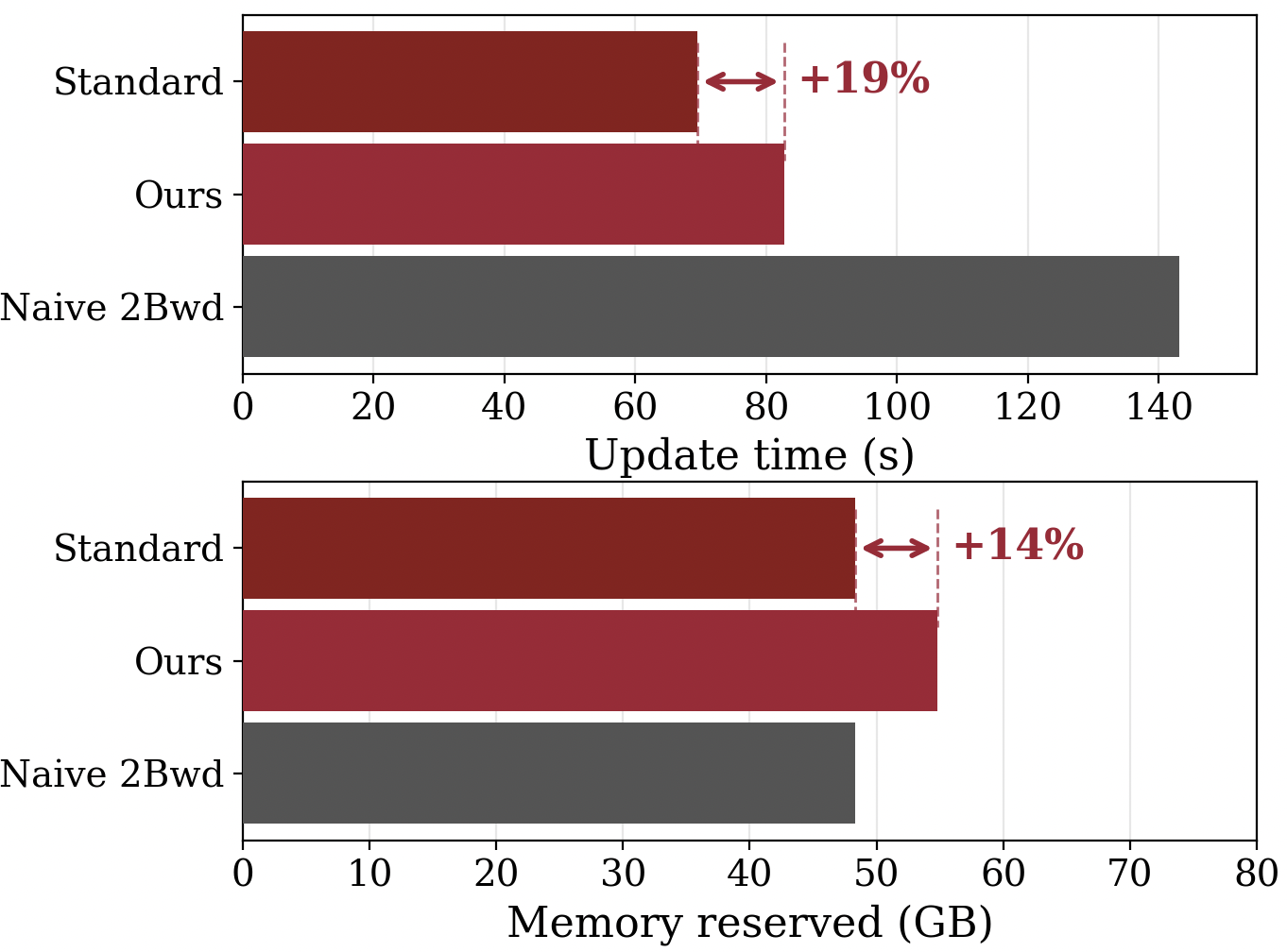
With this implementation, we only have a 19% compute time overhead instead of a 100% overhead, with only additionally 14% memory overhead.
7. Results
8. LLM Post-Training in 2026 (and Beyond)
How We Compute It Efficiently
0.1 Previous Approaches
Previous approaches to stabilizing (possibly asynchronous) RL include:
- Masking / clipping mechanisms: M2PO, IcePop, sequence-level IS ratio masking, TIS, and DeepSeek masking.
- Algorithmic changes: trajectory balance asynchrony, GSPO, sequence-level importance sampling, and optimal token baselines.
- System-side changes: fp16 inference and training, and rollout routing replay.
1. VCPO: Robust, Scalable Asynchronous Post Training
1.1 Off-policy staleness => Importance weights blow up => ESS collapses
In asynchronous RL, the trainer updates \(\pi_\theta\) while rollouts are generated by a stale policy \(\mu\). The policy gradient uses importance sampling weights. As staleness grows, KL grows, log-ratios become heavy-tailed, and a few trajectories dominate the update: one sample rules them all.
Effective Sample Size summarizes this. Interpretation: your update behaves like it only used \(\mathrm{ESS}\) samples, so variance scales roughly like \(1/\mathrm{ESS}\). Practical symptom: when ESS collapses, gradients spike and KL runs away.
Thus, motivated by the square-root scaling law for adaptive optimizers such as AdamW, we propose learning-rate scaling via an effective batch-size rule. Because even on-policy/synchronous training can have \(\rho_{\mathrm{ess}}^{\mathrm{on}}<1\) in practice, we introduce an empirical on-policy reference estimated from one step of an on-policy run, or a running average of a few steps. We then rescale the step size by the relative reliability of the batch.
This scaling preserves the on-policy step scale when \(\rho_{\mathrm{ess}}\) is near the on-policy reference, and automatically shrinks updates as \(\rho_{\mathrm{ess}}\) collapses.
1.2 Off Policy Optimal Baseline: A Closed Form Solution for Minimum Variance
Subtracting a baseline does not change the expected gradient, but it can reduce variance. In group methods people often use the mean reward within a group. That implicitly assumes each sample contributes equally to the parameter update. But in reality, different samples and tokens have very different gradient magnitudes. The baseline should weight rewards by how much they actually move parameters.
For per-sample gradient vectors \(g_i\) and IS weights \(w_i\), the variance-minimizing scalar baseline is OPOB. Samples with bigger \(\lVert g_i\rVert\) are the ones injecting most variance into the parameter update, so they should dominate the baseline.
1.3 VCPO
- Compute \(\lVert g_i\rVert^2\) per sample.
- Replace mean reward baseline with the grad-norm-weighted baseline.
- This reduces gradient variance without learning a critic.
- Current implementation note: computing \(\lVert g_i\rVert\) via a second backward pass costs 2x step time.
- Clear optimization target later: use kernels that return gradient norm.
2. Empirical Evaluation
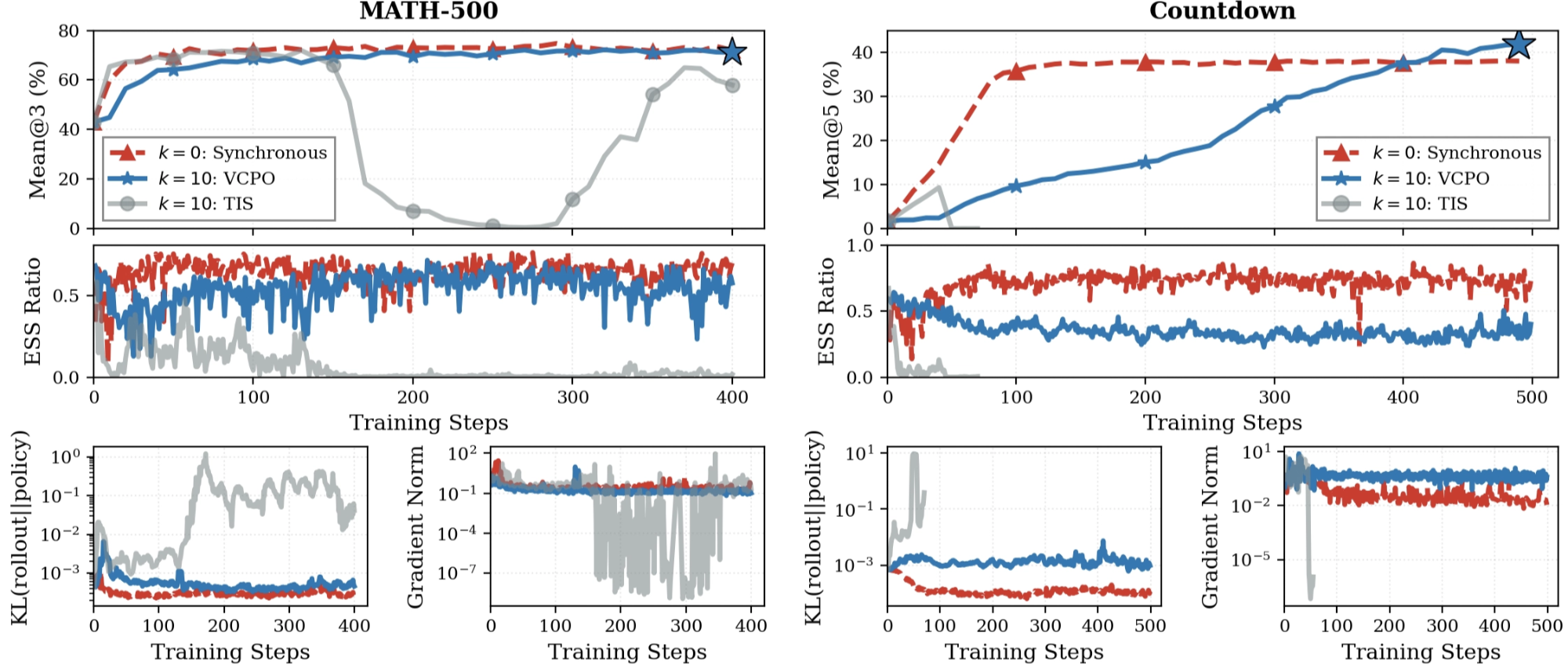
2.1 VCPO Matches Synchronous Performance with Better Throughput
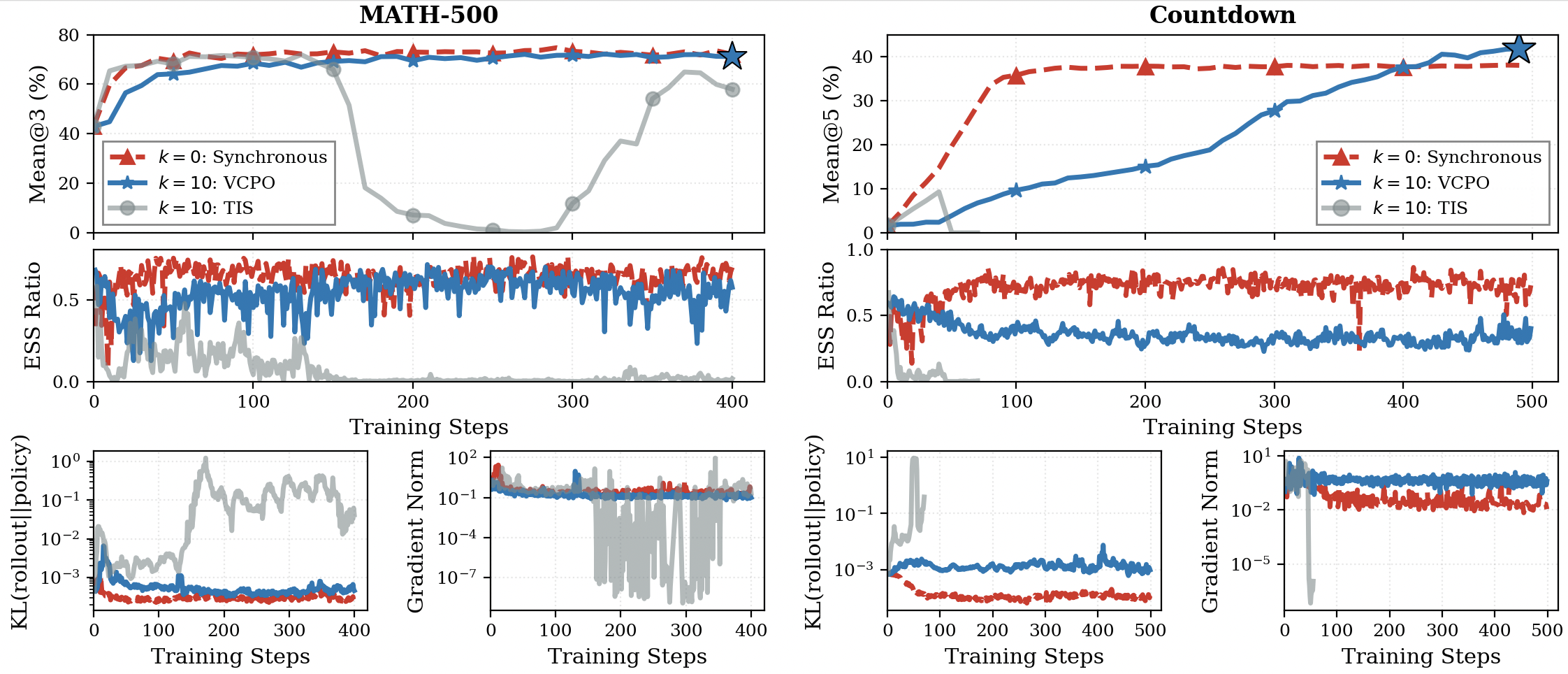
2.2 VCPO Provides State of the Art Stability Under High Asynchrony
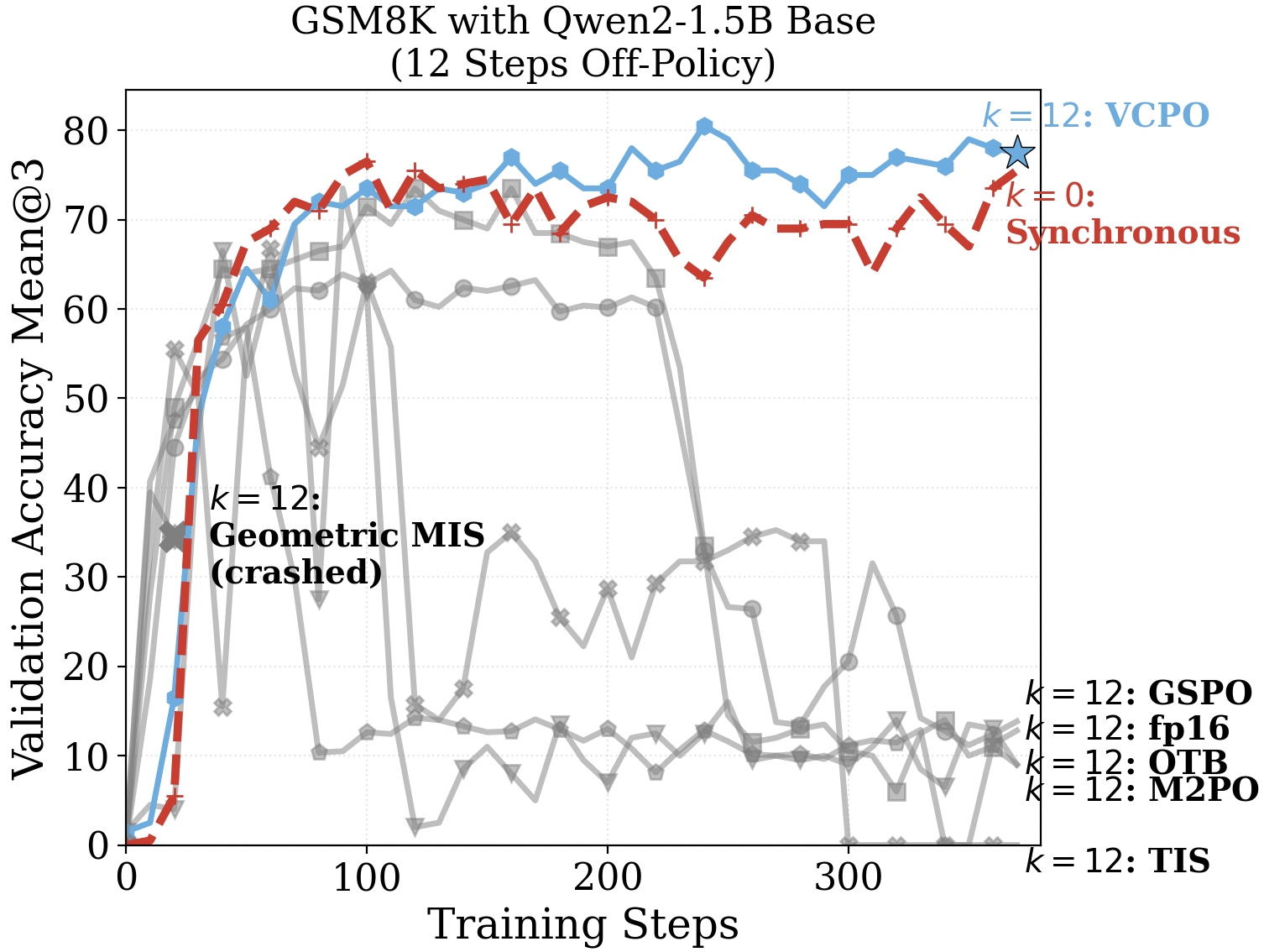
Previous algorithmic and systems changes solutions are not enough.
- Optimal Token Baseline and Sequence Level Importance Sampling collapses.
- Using fp16 leads to a training crash and KL explosion.
2.3 Unlocking Full Effectiveness of Async RL
2.5x speedups on long-context tool-integrated reasoning.
Future Work
- FP8 rollouts + training in the production throughput setting. FP8 is the standard to scale RL throughput.
- MoE models and routing logic.
Citation
@article{
title = {Stable Asynchrony: Variance-Controlled Off-Policy RL for LLMs}
author = {Luke J. Huang, Zhuoyang Zhang, Qinghao Hu, Shang Yang, Song Han},
year = {2026},
month = Feb,
url = {https://arxiv.org/abs/2602.17616}
}